Incode’s Frontier AI Lab addresses the rapid evolution of fraud driven by artificial intelligence. It develops models to counter adversarial attacks, leverages global data, applies continuous learning, and validates outcomes through benchmarks and large-scale deployments to safeguard digital trust.
Fraud is accelerating with the rise of generative AI. Deepfakes, synthetic identities, and automated impersonation agents can be created and deployed at scale, producing adversarial attacks that evolve as quickly as the underlying technology.
Solution
Incode develops foundational models for identity, document, and behavior analysis. These models are trained on proprietary datasets and designed to adapt in real time to adversarial fraud attempts, staying ahead of evolving AI fraud.
VLM, LLM, Agent
Multimodal and Agentic Models for Real-Time Fraud Adaptation
Incode develops Vision-Language Models, Large Language Models, and intelligent agents to automatically react to and continuously learn from emerging Gen-AI fraud threats , enabling the system to adapt in real time, detect novel attacks in seconds, automate responses, and, ultimately, defeat them.
Incode VLM is trained on images and videos of faces and ID documents to detect tampering, altered IDs, synthetics, and deepfakes. It also supports classification, OCR, data extraction, and automated Q&A across biometric and document signals
Status: Live in production and deployed across enterprise environments worldwide.
Use Cases: Deepfake and tamper detection, document classification, OCR, and cross-checking visual/textual consistency.
Training: Millions of global faces and documents, including templates and synthetic fraud samples across 200+ regions.
Learning: Few-shot learning enables adaptation to new gen-AI attack types and document formats.
Performance: Superior accuracy vs. traditional ML classifiers in production benchmarks and fraud simulations.
Fraud Large Language Models (LLM)
Incode LLMs are trained on world knowledge and proprietary datasets that fuse identity, document, behavioral, device, transactional, and risk signals. They analyze data in real time to detect patterns and extract signals across large, complex datasets.
Status: In training, with early launch expected in 2026.
Use Cases: Data analysis, signal extraction, anomaly detection, pattern matching, fraud-intent classification.
Training: Proprietary fraud datasets, global identity data, synthetic fraud attempts, and structured metadata (e.g., behavioral signals, device headers, transaction flows).
Learning: Designed for few-shot and transfer learning, allowing adaptation to novel fraud methods and contextual manipulation attempts.
Performance: Early internal testing shows significant gains over traditional rule-based and ML classifiers.
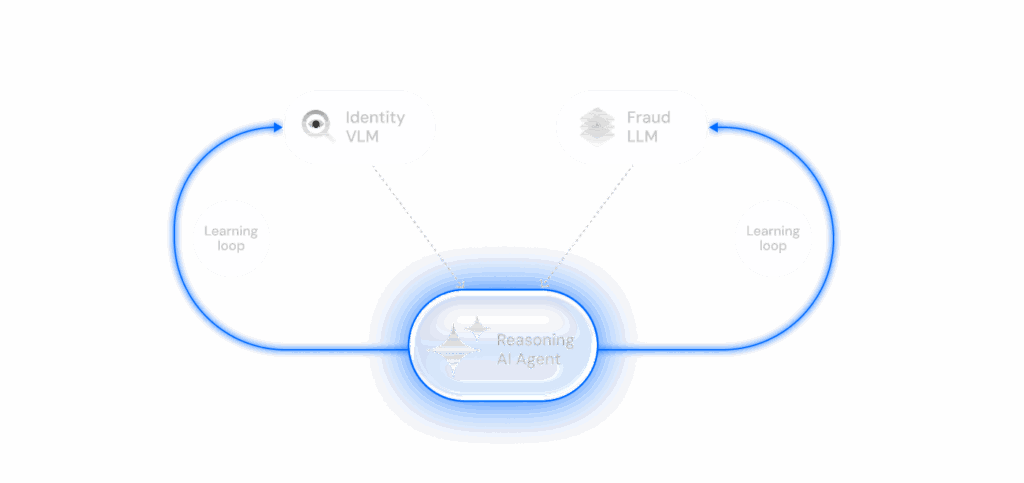
Reasoning -Risk Agents – Multimodal Intelligence
Incode Agents are AI orchestration systems that coordinate multiple models and datasets. They integrate outputs from VLMs, LLMs, risk signals, and public internet sources with internal insights into a unified decision process, enabling holistic case-level decisions in real time
Status: Live in production and deployed across enterprise environments worldwide.
Use Cases: Evaluates a broad set of signals holistically to deliver real-time, context-aware risk decisions.
Training: Built on hundreds of signals and millions of sessions labelled with fraud outcomes. The system adapts to each client by learning from their history of false approvals and false rejections, improving accuracy while reducing mistaken blocks of legitimate use.
Learning: Continuously improves through reinforcement from live outcomes and human analyst feedback.
Performance: Designed to minimize human intervention while improving error rates. Early Risk AI Agent results show reduced fraud and higher approval rates for genuine users.
Mexico:
FAR improves by ≈47.6%
FRR improves by ≈60.3%
USA:
FAR improves by ≈12.1%
FRR improves by ≈19.1%
Data
Comprehensive Training Data
Incode’s access to a massive, proprietary global dataset, combined with early insights from high-fraud markets and continuous learning, creates a comprehensive foundation that powers resilient AI fraud defenses
Large-Scale Data
Global coverage and scale for training resilient models- Incode leverages data from government databases, enterprise integrations, and billions of verification events worldwide. This scale provides the diversity and depth required to train models with broad regional coverage and resilience against a wide range of fraud tactics.
Global Coverage
200+
Countries
4,600+
Document types
Data at Scale
400M+
Unique Identities
4.1B+
Identity checks
Enterprise Coverage
700+
Enterprise clients
20+
Industries served
Source of Truth Data
500+
Access to trusted database (Telcos, govt records, financial databases, +)
15+
Biometrics government source of truth connections
Fraud Data Infrastructure
Turning global data signals into real‑time fraud defense intelligence.
Incode converts large, diverse data into clean training and testing signals. We label at scale, generate realistic edge cases, and pressure‑test models so they improve with every new attack pattern, enabling proactive defenses that act early and stay ahead of regional and emerging fraud trends
Labeling Pipelines
Human and automated review across millions of records
200+ human labelers
Synthetic data
120+ synthetic data generation tools.
Generation of tampered documents, presentation attacks, and deepfakes to train models on rare threats
Fraud Lab
Red‑team environment to create and replay real attack scenarios
40+ AI engineers
Fraud‑rich signals
Targeted inputs from high‑risk regions and industries
Continuous feedback loop that retrains models as tactics evolve
Access to the best training data for fraud prevention
Models trained with high-fraud regions data
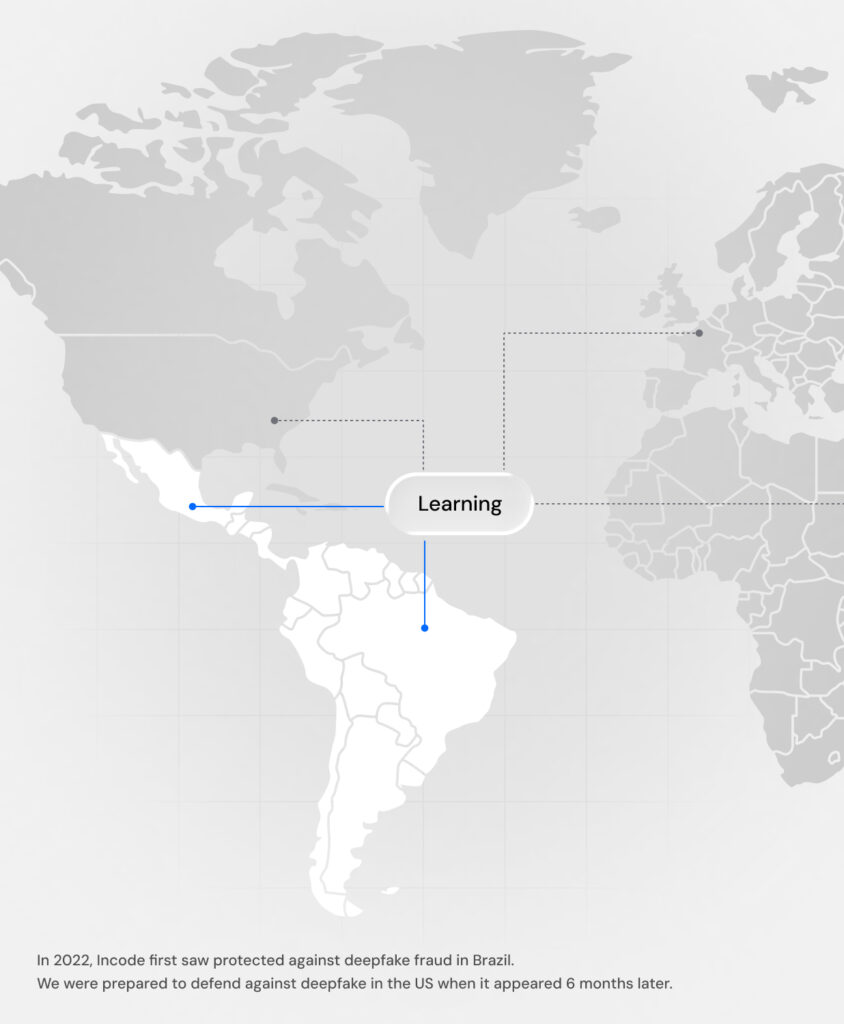
Incode has extensive reach and expertise in Latin America, covering 66% of the adult population, operating in the highest-fraud regions Brazil (12× U.S. fraud) and Mexico (4× U.S. fraud). This environment provides exposure to complex attack methods and evolving fraud patterns that enable our models to be trained and stress-tested against emerging threats before they spread to other regions such as North America and Europe, strengthening our global fraud prevention performance.
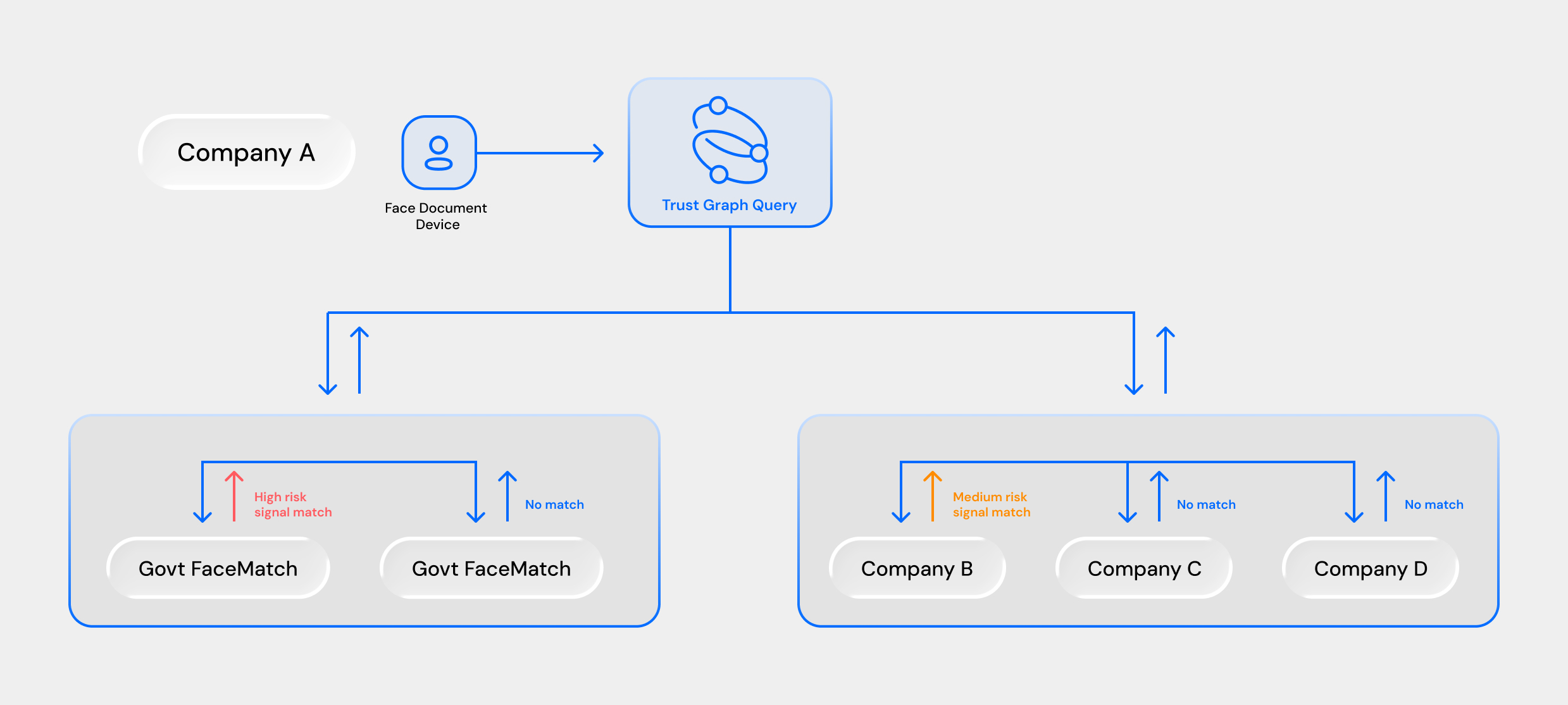
Trust Graph
By combining broad data coverage with structured training inputs, Incode converts heterogeneous signals into early, reliable fraud indicators. These indicators feed Incode’s Trust Graph, which aggregates risk patterns across clients to identify and block recurring behaviors while maintaining privacy safeguards
Desgined for storing and searching facial embeddings at scale, it supports both 1:1 verification, matching a probe to a claimed identity, and 1:N identification, where probes are compared against large galleries to find the best matches.
Performance
20–40 ms search times across hundreds of millions of vectors
Elastic Resilience
Vector indexing, sharding, parallel querying, and autoscaling
Efficiency
Caching reduces tail latency for frequent queries
Security
Built-in encryption, retention controls, and auditability
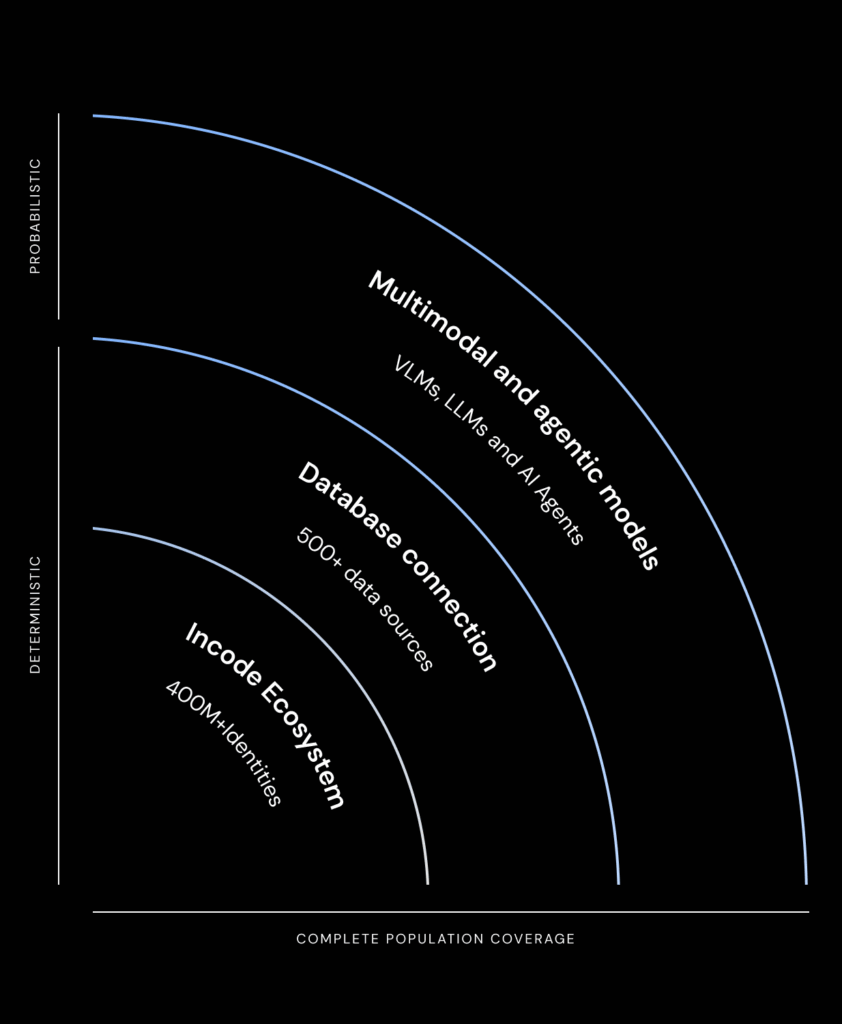
Complete Population Coverage Through Deterministic and Probabilistic Data
Unified Coverage
Together, deterministic anchors and probabilistic intelligence deliver 100% population coverage. This layered design powers continuous learning, enabling models to adapt quickly and strengthen fraud prevention ahead of emerging threats
Probabilistic Data
Multimodal and agentic models VLMs, LLMs and Intelligent Agents extend coverage to new identities outside deterministic sources.
Deterministic Data
Incode’s Ecosystem
400M+ identities confirmed by Incode, provide a foundation of verified identities that anchor model accuracy (e.g., 65% of USA adults)
Official Identity databases connection: 500+ official data sources, this data feeds into Incode’s confirmed identities and continuously improve model training.
End-to-end face perception that detects faces, creates robust embeddings, and matches identities at scale via a vector engine, continuously improving through calibration and hard‑case mining.
3rd Party Validation
Nist #1 technology ranked for facial recognition
1:1 NIST Certified
1:N NIST Certified
FIDO Face certification
DHS RIVTD: Incode was one of only 3 vendors to meet all key benchmarks (FTXR <1%, FNMR <1%, FMR below 1:10,000).
Generic Face Detector
Detects and localizes faces in selfies and ID images, serving as the foundation for downstream tasks such as recognition, liveness, and document validation. The model is trained to handle varied image conditions, including rotation, occlusions, and non-human distractors. Evaluated on datasets covering selfies, IDs, rotated samples, negatives, and non-human inputs.
Face Recognition 1:1
Performs one-to-one biometric matching by comparing a live selfie against the portrait extracted from a government ID. The model is optimized to minimize both false accepts and false rejects under strict thresholds. Evaluated on a dataset of 5.8M+ selfie–ID pairs.
Face Recognition 1:N
Performs one-to-many biometric search by embedding a live selfie into a high-dimensional feature space and comparing it against a gallery of enrolled identities. The model is designed for scalability and efficiency, supporting large databases while maintaining strict accuracy thresholds. It minimizes false accepts and false rejects through optimized indexing and similarity scoring. Evaluated on a dataset of 5.8M+ selfie
FaceDB (Vector Matching Engine)
A vector database and matching engine for facial templates. It enables 1:N identification and 1:1 authentication by converting faces into embeddings (high-dimensional vectors) and comparing them efficiently. Built as a C++ binary with an Elixir orchestration layer, FaceDB uses HNSW indexing for similarity search and supports both standalone and clustered deployments with autoscaling and index migration.
Multi-modal defenses that distinguish real users and physical IDs from spoofs and deepfakes using spatial, temporal, and device-aware signals with continual hard‑negative training.
3rd Party Validation
1stPassive Liveness technology to be certified in the market
Face Liveness: Detects whether a selfie comes from a live human rather than a spoof (photo, screen replay, mask, or deepfake). Incode’s default passive liveness has been evaluated on a dataset of 150,000+ spoof attempts, covering replays, paper copies, 2D masks, and 3D masks.
Document Liveness
Document Liveness: Determines whether an identity document presented to the camera is a genuine physical ID or a spoof (printed copy, photo, or screen replay). Paper ID Liveness v5.0 has been evaluated on a dataset of 34,000+ spoof attempts, covering paper copies and screen replays across diverse document types.
Deepfake and Gen‑AI Defense: Multi‑modal models that detect and block AI‑generated fraud , deepfakes, face swaps, document injections, and synthetic identities, by combining pixel‑level artifact analysis with generative‑pattern inconsistencies and cross‑signal checks across face, liveness, document, barcode, and metadata inputs
3rd Party Validation
#2 in the ICCV 2025 DeepID Challenge, a benchmark focused on detecting Gen-AI generated identity documents.
Ranked #1 in deepfake attack detection by Hochschule Darmstadt, outperforming commercial vendors and research labs
Deepfakes
Digital Liveness (Deepfake & Injection Detection): Detects whether a selfie has been synthetically generated, altered, or injected (e.g., face morphs, swaps, or AI-generated deepfakes). Evaluated on a dataset of 40,000+ digital spoof attempts
Gen-AI Documents
Digital Liveness (Deepfake & Injection Detection): Detects whether a selfie has been synthetically generated, altered, or injected (e.g., face morphs, swaps, or AI-generated deepfakes). Evaluated on a dataset of 40,000+ digital spoof attempts
Learn more about Incode’s Liveness detection technology
Age Assurance and Core Models
Policy-ready age estimation that provides calibrated predictions with uncertainty bounds and fairness constraints, routing edge cases to secondary verification.
3rd Party Validation
NIST: Each model ranked among the top 3 in the market for the lowest average MAE across all ages
NIST: Fastest Response Time among age verification vendors for Age estimation
ACCS accreditation under PAS 1296 (Age Check Certification Scheme, UKAS‑accredited)
Age Estimation
AI model that estimates a user’s age from a selfie, designed to enforce age-based compliance while minimizing bias across demographics, trained on data from over 200,000 images.
Document understanding that classifies type, extracts and validates OCR, MRZ, and barcodes, and detects tampering, fusing signals into a document authenticity score that adapts with active learning.
Document Type Classification
Determines the category and regional origin of an identity document by analysing its visual layout, textual content, and structural patterns. The model leverages multimodal machine learning techniques to distinguish between document types and issuing authorities, even under varied formats and scan conditions. Evaluated on a large-scale dataset of diverse global identity documents
Tamper Detection
Detects whether the portrait or key fields on an identity document have been digitally manipulated (e.g., replacement of the main photo, text-field alterations, or other digital edits). The model leverages pixel-level anomaly detection and cross-template consistency checks to identify tampering. Evaluated on a dataset of 8,200+ tampered ID samples.
ID Text Readability
Determines whether the text fields on an identity document are readable for automated data extraction. The model processes cropped ID images with a binary mask over text zones and classifies them into three categories: unreadable, no text fields of interest, readable. Evaluated on both test and production datasets, it shows significant improvements over earlier segmentation-based approaches.
ID Cropping (Web + Mobile).
Detects and crops identity documents from camera frames while also estimating text and barcode readability, as well as image quality factors such as blur and glare. Both models are designed to ensure that captured IDs meet readability standards for automated processing, across mobile and web environments.
Barcode Validation
Ensures that barcode data extracted from identity documents is correct, complete, and compliant before use downstream. The model performs multiple layers of validation, including: Symbology Checks: Confirm the barcode type (e.g., PDF417) and enforce structural rules.
Decoding Integrity: Verify error-correction and checksums; perform re-encoding round-trip checks.
Spec Compliance: Validate against standards (e.g., AAMVA), required fields, delimiters, and length constraints.
Data Consistency: Cross-check fields against OCR/MRZ and validate logical values (DOB, expiration, issue date).
Security & Anti-Tamper: Detect truncation, padding abuse, malformed segments, and flag anomalies or signature/hash mismatches.
Fraud & Risk Defense
A real-time orchestration layer that combines model outputs with a trust graph to score and route risk decisions, optimizing thresholds through continuous feedback and counterfactual evaluation
Risk AI agent
Integrates 100+ tabular features from face, document, liveness, and event signals to estimate the probability that a session is fraudulent. The model reduces the need for manual reviews while improving fraud detection and approval rates for legitimate users.
Trust Graph
A fraud defense layer that links users, devices, sessions, and documents to uncover coordinated attacks. It maintains a global fraud list and connects traces like faces, device hashes, and document numbers, flagging anomalies such as shared devices, repeated IDs, or deceptive personal details.
Trace Types: Face, Face-on-ID, Device Hash, Document Number, Personal Number, Voter Number
Global Fraud List: Continuously updated across clients
Evasion Fraud
A model designed to block advanced fraud attempts that try to bypass liveness and face-recognition systems. It targets adversarial behaviors such as extreme expressions, partial or half-masks, occlusions, and other attempts to manipulate on-device capture. The model was evaluated on a dataset of 54,000 samples collected from production environments, representing real-world evasion scenarios.
Device and Behaviour Intelligence
Machine learning models that analyze device, network, and user-interaction signals to assess session integrity and risk. Inputs include hardware and OS characteristics, network attributes, emulator or automation indicators, and behavioral telemetry such as typing cadence, swipe velocity, or cursor movement. The models identify anomalies, automation, and high-risk usage patterns
Behavioural Model
Machine learning models that analyze patterns of human interaction to assess authenticity and risk. Inputs include typing cadence, keystroke dynamics, swipe velocity, scrolling behavior, and cursor movement. These models detect anomalies such as scripted activity, replayed interactions, or unusual usage patterns that may indicate fraud or automation
Device Signal Model
Machine learning models that evaluate the integrity and risk profile of the device and network used in a session. Inputs include hardware and OS characteristics, browser and app attributes, IP and network indicators, emulator or automation flags, and sensor data. These models identify signs of compromised, emulated, or suspicious devices to prevent unauthorized access and fraud.
Governace
Comprehensive governance framework covering data practices, security, model development, fairness, and compliance to ensure responsible AI